
AI Amplifies Expertise. It Doesn't Replace It.
By Shane Argo, CEO, All the Ducks
When Claude Code suggested an approach to a problem during a recent project, the AI suggestion almost always sounded reasonable. The code samples compiled, the plans read like the kind of plan an engineer would write, and the recommendations referenced real libraries and real patterns. Most of the time the suggestion was right, and when it wasn't, the difference was usually clear to me. It wouldn't necessarily have been clear to someone without my background.
An expert and a non-expert facing the same problem don't get the same answer from the same AI tool, because the expert knows what to ask and how to read what comes back.
If you work in IT or software, you'll know the feeling of watching a TV show where someone "zooms and enhances" a pixelated photo, or breaks into a server by typing furiously against a wall of green text. The depiction looks convincing if you don't know any better, and complete nonsense if you do.
That same gap shows up with AI output. The answer looks competent, by which I mean it carries the surface markers of a good answer: confident phrasing, references to real concepts, and structure that resembles what a knowledgeable person would produce.
A poorly worded answer warns the reader to think twice. A confident, plausible, and plain-wrong answer rarely sends the same warning, which is why it gets accepted and acted on.
What the research shows
A study by researchers at the Oxford Internet Institute, published in Nature Medicine in February 2026, tested whether members of the general public could safely use large language models on ten realistic medical scenarios. The study involved 1,298 UK participants and three different LLMs (GPT-4o, Llama 3, and Command R+).
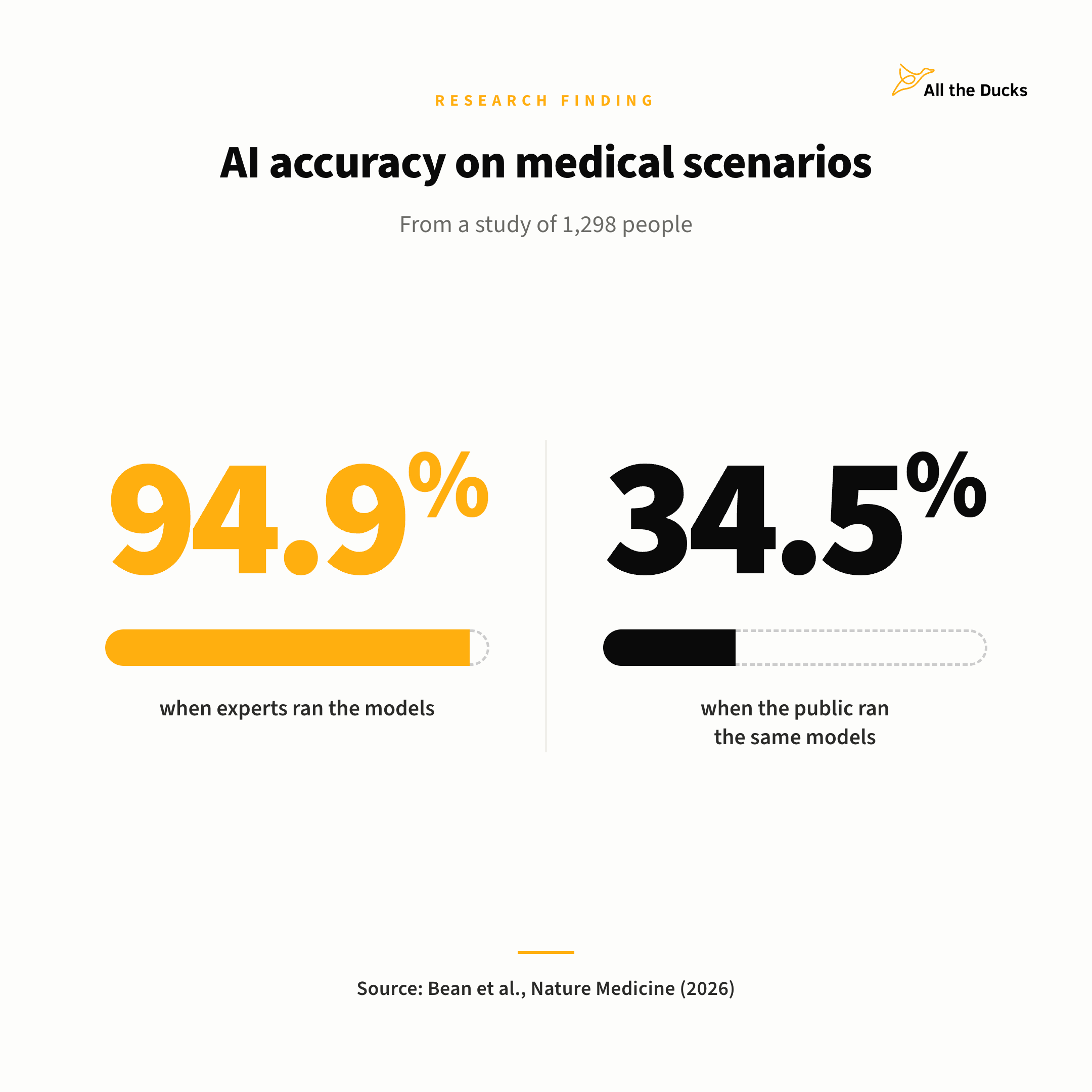
When the researchers, the discipline experts, fed each model the full scenario as a single written prompt, the models correctly identified the relevant medical conditions in 94.9% of cases. When members of the public were instead given the scenario as if it were happening to them, with no prior knowledge of what was being tested, and had to describe their situation to the model through a chat conversation, fewer than 34.5% of responses identified the relevant conditions, no better than a control group using internet search or their own knowledge. The authors put it directly: "Strong performance from the LLMs operating alone is not sufficient for strong performance with users."
The same model, working on the same scenarios, produced safe answers when researchers were directing it and unsafe answers when ordinary people were. The difference was in who was sitting between the scenario and the response, what they thought to ask, and what they did with what came back.
That research lines up with what we've been seeing in our own work. The gap is in the non-expert, not the AI: it is in not knowing what to ask, and not knowing what to push back on in the answer.
How we built the Permissions Planner
Earlier this year we published the Canvas Permissions Planner, a tool that maps every Canvas API endpoint to the role permissions that need to be granted. The tool was built entirely with AI assistance. That phrase tends to invite scepticism, and it should, because there are plenty of AI-built ("vibecoded") things in the world that look fine until you push on them and discover they are not. The Permissions Planner is publicly available, and the source is on GitHub, so you don't have to take our word for whether it holds up.
The reason it does hold up is that I spent far more time writing plans than writing code. I have not written any of the project's code, but I have read and approved every line of it. The plans drew on knowledge of Canvas, LTI integration, accessibility, and software architecture from work we do every day, and they were not the plans Claude would have written on its own.
The shareable URL feature is one small example of what that meant in practice. The AI's first instinct was to encode every selected endpoint as a separate URL parameter, which would have worked technically and broken in practice the moment a user selected thirty endpoints. Redirecting the AI to a different encoding scheme took a minute or two of conversation, and the alternative was built quickly once the direction was set. Hundreds of moments like that one are buried across the build, most of them invisible to anyone reading the finished code.

Three patterns from those moments stand out.
First, there were architectural choices where the AI's suggested approach was technically valid but wouldn't have held up in practice. The Permissions Planner is driven by a public JSON file of around 464 API endpoints, fetched at runtime, and Claude's first instinct was to use the data directly. I knew from working with this kind of fetched data that you always validate it before trusting it, so we put a schema in front of it.
The change didn't alter what the tool does. It changed how it fails when something goes wrong, which is the kind of decision an expert makes by reflex.
Second, the AI made improved functionality through UI polish economically feasible. That meant dark mode, a copy-to-clipboard helper, sensible print stylesheets, and decent accessibility coverage. I have the skills to write all of those, but for a free, open-source side project I would not have spent the time on them.
With AI, it was a matter of asking, reviewing, and shipping. The result is not a more polished tool than I could have built, but a more polished tool than I would have built. That distinction matters because it changes the economics of every small-team project, not just this one.
Third, and most striking, AI made things feasible that simply weren't before. The dataset itself was assembled by pointing Claude at the Canvas source code on GitHub and asking it to work out which permission each endpoint requires. By hand, the work would have been prohibitive for a community contribution and would simply not have happened.
The same pattern shows up across our other work. Michael has been using Claude to produce an OpenAPI specification for the Canvas API, because the spec generator built into Canvas itself is outdated and incomplete. A usable spec was previously too expensive to maintain by hand, and with AI plus an expert reviewing every section, it is now tractable.
What this means for universities
Tools alone don't replace expert teams, and tools paired with expert teams produce a higher quality ceiling than either alone. The gap shows up in exactly the places that matter: the architectural decisions a non-expert wouldn't catch, the polish a non-expert wouldn't know to ask for, and the scope a non-expert wouldn't even attempt.
At All the Ducks we call this Hybrid Intelligence. The expert sets direction, the AI moves fast, and the expert evaluates what comes back. Both are needed, and one does not replace the other.
For universities thinking about AI in their own work, the question has shifted from whether AI can do the work to whether you have the people who can judge whether the work is any good.
The Canvas Permissions Planner is online. The original Insights post walks through how we built it.